
yallmap — Yet Another LLM Proxy
Why build yet another LLM proxy?
I’ve been using Claude Code for AI-assisted development, as I’ve described in earlier posts. I really enjoy the broad feature set of Claude Code as an LLM client, though there are a few things I’d like to improve. How many tokens am I actually burning? What models am I using? I’m on a subscription plan, but what’s the actual cost of my model spend? Finally, if I want to dynamically use other models, particularly local open-weight models, how can I use them in Claude Code with all the visibility that I want? Claude Code doesn’t come with that functionality.
A big part of answering these questions is using an LLM proxy. Using an LLM proxy you can implement custom model routing and telemetry. This is already a big market — LiteLLM, Helicone, and Portkey are already out there. However, they are all built from the OpenAI perspective, with Anthropic as a translated dialect on top. I wanted to try making a proxy that conforms to the Anthropic Messages API, so that I could use it as the target of Claude Code’s ANTHROPIC_BASE_URL.
Hence I built yallmap — Yet Another LLM Proxy. Finally, I get to use both y’all and map in a product name (an inside joke for those who know how much I love maps and geography, and that I’m Southern). It’s an Anthropic-native gateway in TypeScript, with OpenTelemetry traces shipped to a self-hosted Langfuse instance — eventually destined for the Raspberry Pi cluster from my Kubernetes post. The whole thing is on GitHub at kckempf/yallmap.
What it does
The basic picture:
Claude Code ──► yallmap :3001 ──► api.anthropic.com
│ └──► Ollama (local models)
│
└──► Langfuse (via OTLP)
gen_ai.request.model
gen_ai.usage.input_tokens
gen_ai.usage.output_tokens
gen_ai.response.finish_reasonsPoint Claude Code at it:
ANTHROPIC_BASE_URL=http://localhost:3001 claudeEvery request to POST /v1/messages then goes through a TypeScript service built on Hono, with undici handling the streaming requests. Streaming responses are piped through a Transform stream that reads the SSE events in flight to extract token usage and finish reasons without buffering or blocking. On request completion a single OTel gen_ai.request span is emitted, which includes the model, token counts, cost, and latency. This is sent to a Langfuse OTLP endpoint, unless you want to send to an alternative OTLP endpoint (I’m using Langfuse myself so that’s the default). In Langfuse I can see at a glance what kind of AI use I’ve had in the last day, or dive deeper into the traces.
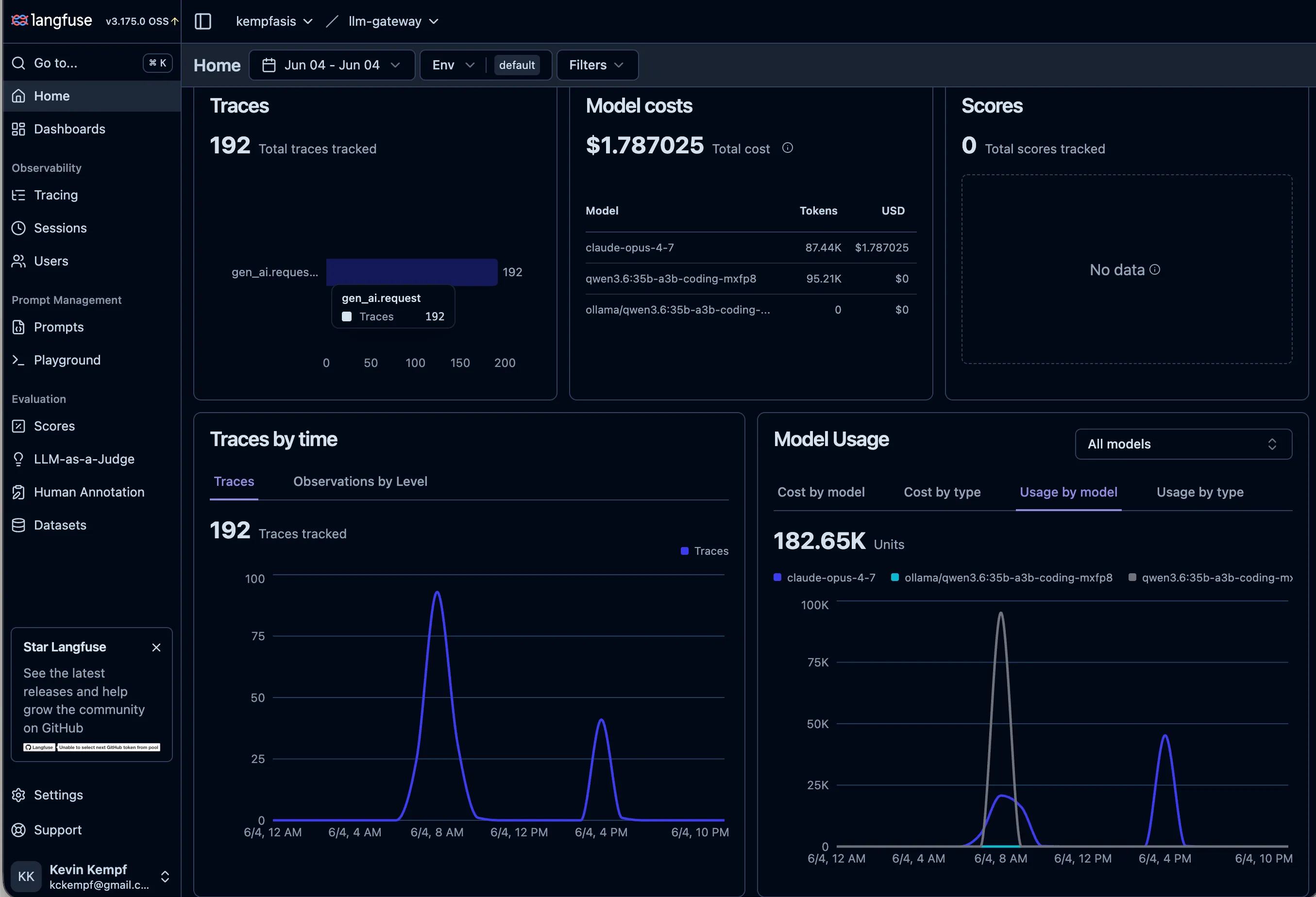
That much was very cool, but once I had a proxy in place, it opened up the possibility of other uses, such as routing.
Routing in TypeScript
In other LLM proxies, routing is typically defined using YAML. While I am generally fine with YAML, I wanted to try defining the routing in TypeScript, as it offers advantages such as strict typing:
import { firstMatch, whenModel, chain, anthropic, ollama } from './index';
export const router = firstMatch([
// ollama/* models hit the local Ollama; if it fails, fall back to Anthropic
whenModel(/^ollama\//i, chain(ollama, anthropic)),
]);firstMatch, whenModel, chain are all typed functions, rather than config keys. To add a new rule like “send any request over 50K tokens to a long-context model” or “route a specific Claude Code session to a cheaper model”, write a predicate. The TypeScript compiler gives early feedback for any syntax errors, and the behavior can be confirmed in unit testing.
A native-to-OpenAI adapter for Ollama
The recent switch to metered billing by Copilot, while not unexpected, highlights one of the big risks of relying on AI-assisted development. The past couple of years of AI-assisted development have been heavily subsidized by providers who wanted us to learn their potential before being turned off by sticker shock. Knowing the pricing hit on the horizon, I’ve been experimenting with hosting open weight models locally. With a good Macbook Pro setup I can run a 35B-parameter model in 4-bit quantisation, with responses often coming back faster than Claude for some questions. I’d like to run experiments with my local model in Claude Code, but Ollama uses the OpenAI Chat Completions shape while Claude Code expects Anthropic Messages.
To bridge that gap, yallmap ships with an adapter that translates Anthropic-shaped requests into OpenAI-shaped Ollama requests on the way out, and back into Anthropic-shaped responses on the way home. Tool use, tool results, /no_think for thinking models, and various sampling parameter aliases are all handled in this layer.
Middleware
As a Hono web service, middleware in yallmap is in the form of functions of the form (ctx, next) => Promise<Response>. The composition is typed at compile time, and I’ve shipped a few basic middleware functions with the first version.
import { costGuard, rateLimit, apiKeyAuth, piiRedactor } from './index';
export const middlewares: MiddlewareFn[] = [
apiKeyAuth({ keys: process.env.GATEWAY_API_KEYS }),
costGuard(0.10), // reject if worst-case > $0.10
rateLimit({ requests: 100, windowMs: 60_000 }), // 100 req/min per key
piiRedactor([/\b\d{3}-\d{2}-\d{4}\b/g]), // redact SSNs from prompts
];costGuard multiplies max_tokens by the current pricing table and rejects with a HTTP Status 429 before the request ever leaves the gateway. rateLimit is a fixed-window counter, keyed by API key when authentication is enabled. apiKeyAuth does a multi-key allowlist with per-key identity that propagates into logs and trace spans, so I can see which key drove which traffic.
The middleware paradigm makes it easy to compose custom middleware. If I want to use Opus on Monday, Sonnet on Tuesday, and Qwen Coder on the other days, I can write it using a TypeScript function.
Multi-key authentication, optional
yallmap uses API keys set using the GATEWAY_API_KEYS environment variable for its authentication. When this variable is unset, yallmap runs unauthenticated — fine for local development, but unsafe for a publicly exposed deployment. A startup warning is logged when NODE_ENV=production and no keys are configured.
GATEWAY_API_KEYS=alice:abc123,bob:def456,ci:ghj789With this setting, clients must send x-gateway-key: <secret>. The matched label flows into structured logs (keyId) and Langfuse spans (user.id). The label is the half that’s safe to log; the secret never leaves the comparison.
The stack
Hono for the HTTP layer, undici for the upstream calls, pino for structured logging, OpenTelemetry SDK for Node.js for traces. TypeScript with strict: true, Vitest for tests. The whole production image is a multi-stage Docker build on node:22-alpine that copies only compiled JS into the final stage — no dev dependencies, no TypeScript source.
I’ve been running self-hosted Langfuse in a Docker Compose stack on my laptop — moving it to the Raspberry Pi K8s cluster will take some improvements in hard disk latency. The OTLP endpoint is one environment variable; if it’s unset, the gateway runs anyway and logs a warning — the telemetry half is optional by design.
Try it
git clone https://github.com/kckempf/yallmap && cd yallmap
npm install
npm run dev # starts on :3001
# in another shell:
ANTHROPIC_BASE_URL=http://localhost:3001 claudeLangfuse is optional; without it, you still get structured request logs to stdout. With it, you get a per-request span timeline. You can get up and running quickly in Langfuse with their Docker Compose deployment.
What’s next
I haven’t decided for sure where to go next with yallmap, but I’ll let my own use of it guide where it goes next. Per-key cost budgets could be useful as providers move to metered billing. A Prometheus /metrics endpoint could also be very useful. I’ll be working at some point on a CDK construct for deploying to ECS Fargate, for users who want to quickly deploy to the cloud.
I encourage you to use this yourself, and feel free to provide feedback and contributions on GitHub.
Comments
No comments yet. Be the first to reply on Bluesky!